

With so much of our daily lives aided by technology, it’s nearly impossible for our personal information to stay offline. Worse, frequent data breaches of supposedly secure platforms mean that information is increasingly likely to fall into the hands of someone with malicious intent: According to Security Magazine, more than 36 billion personal records were exposed to hackers in 2020—with massive data breaches disclosed by both startups and Fortune 500 companies alike.
So, how can SaaS companies better protect users and keep critical information safe?
With high-profile data breaches reaching even the most well-established technology companies, Sensor Tower is always exploring the best ways to keep user information secure. Because information security is an ever-evolving field, we continue to invest in exceeding industry-standard privacy techniques and investigate the most cutting-edge methods and evaluate how to make our platform even more private and secure with these emerging technologies. One of the most intriguing concepts emerging in this field is Differential Privacy, a novel way to further secure SaaS datasets.
Let’s take a closer look at Differential Privacy, and why we’re so excited about its potential applications in the world of SaaS information security.
What Is Differential Privacy?
From a technical perspective, Differential Privacy is the mathematical formalization of the likelihood that an individual can be identified from released data by intuitively measuring the increased risk an individual incurs by participating in a dataset. In most applications, companies already take only the information that they need to make clear data suppositions without exposing more information than is necessary. Even still, a composite understanding of the different data points taken could potentially and unintentionally result in a user being isolated and identified.
For example, if a malicious actor has access to two datasets that differ by a single person’s data, they could normally identify that person’s data by taking the difference between those datasets. However, when the query is differentially private, the results with or without an individual are essentially the same. This means that regardless of any outside information available, no individual can be definitively said to be included in the dataset.
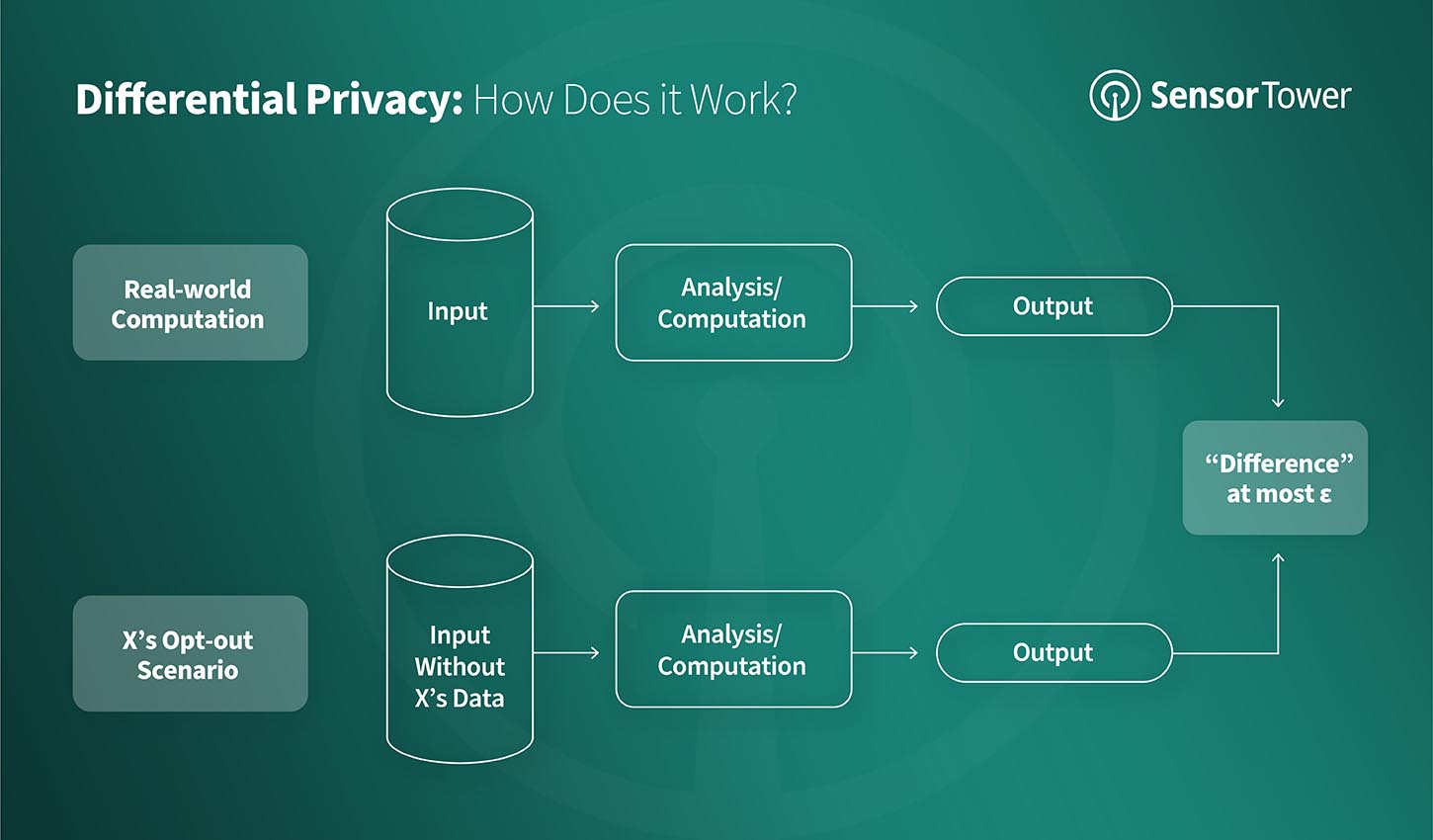
Differential Privacy is often reached when there is enough mathematical “noise” added to a given series of datasets to ensure that outcomes remain consistent no matter what the input, but the question of how much noise and where to apply it is variable. However, sustained Differential Privacy, once achieved, can keep users safe without altering the effectiveness of a given platform.
How Does Differential Privacy Work?
In practice, applying Differential Privacy has some very convenient effects on how datasets can be interpreted without exposing user information. Let’s take a look at the real-word example of a user poll about whether pineapple is a delicious topping on pizza. When querying 100 random users about their pizza preferences, a differentially private mechanism can be utilized during the survey to ensure whomever is looking at the dataset will not know exactly which user enjoys pineapple on pizza:
- When asking the question to a user, have them flip two coins in secret.
- If the user’s first flip is tails, then they should respond truthfully to the question.
- If the user’s second flip is tails, then they should respond truthfully to the question.
- If both of the coin flips result in heads, then they should respond with a lie.
As a result, a truthful answer is received 75 percent of the time and a false answer is recorded 25 percent of the time. So, in this example, no single response can be trusted beyond the 75 percent correct likelihood, giving plausible deniability about which responses were actually recorded truthfully. Therefore, even if a malicious actor were to obtain external information on whether pineapple is an enjoyable topping on pizza, there is no possibility of using that to identify which individuals responded to this question. Even better, the method still produces accurate population statistics on pizza preferences, because although we can’t trust individual data points, the differential within the population statistics is not significantly different.
Differential Privacy is a great way to sufficiently inject a level of deniability into any data set, making contextual comparisons across datasets mathematically much more difficult and keeping users’ personal information much more secure.
Why Does Differential Privacy Matter?
It should be a goal for any technology platform that deals with data to maximize both accuracy and security, and Differential Privacy is another mathematical tool in a vast toolkit that could move the industry even closer to the most accurate, most privacy-centered mobile datasets possible. Exploring Differential Privacy methods seriously, alongside stronger anonymization practices and globally recognized data auditing procedures, is something that all technology companies should consider.
By creating user-sensitive, secure, and private datasets, the mobile data industry as a whole can hope to increase confidence in our practices at every step of the way, from data collection to storage, and even our public-facing models and statistics. Plus, implementing Differential Privacy is a critical practice from a corporate safety perspective, as looking to additional, leading security practices and preventative methods for data breaches becomes imperative for the industry at large. Staying ahead of cutting-edge data breach techniques will ultimately require data that is differentially private to keep our app-focused data safe.
This said, it is still early days in the world of Differential Privacy: Only a handful of major companies are claiming to have found working solutions that optimize accuracy while providing a sufficiently noisy dataset to confuse malicious actors. However, addressing Differential Privacy at several points of the data-handling process—from collection and storage to distribution—while making sure that models and outcomes are fundamentally correct, is worth pursuing. It’s not out of the question that major gains could be made in this space in a short number of years.
Conclusion
Differential Privacy is not a magical cure to data security on SaaS platforms, but it is the next logical step in evolving a platform in such a way that users can feel comfortable using and contributing to it in a meaningful sense. For Sensor Tower in particular, Differential Privacy is an intriguing way to bring formalized mathematical layers on top of the current noise introduction and modeling we already implement to maximize accuracy and security. We’re uniquely positioned to implement Differential Privacy infrastructure because we control our data flow from end-to-end, and deal only in population-level statistics for our Usage Intelligence product. With this information in mind, we’ll continue to discuss our interests in the world of privacy as we continue to improve our understanding and implementation of these cutting-edge methods.
Please continue to follow our blog, Twitter, and LinkedIn to learn more about the improvements our team is making to the Sensor Tower platform at the feature, product, and platform level.
Sensor Tower is the leading, trusted source of enterprise-grade market intelligence and performance metrics in the mobile app ecosystem. Interested in learning more? Reach out and request a demo today.